
Nach einem Jahr voller Experimente, Diskussionen und Entwicklungen haben wir begonnen, unser Modell zu trainieren – ein mehrsprachiges Sprachmodell. Aber wie genau haben wir die endgültige Größe, Form und Dauer des Vortrainings festgelegt?
Skalierungsgesetze
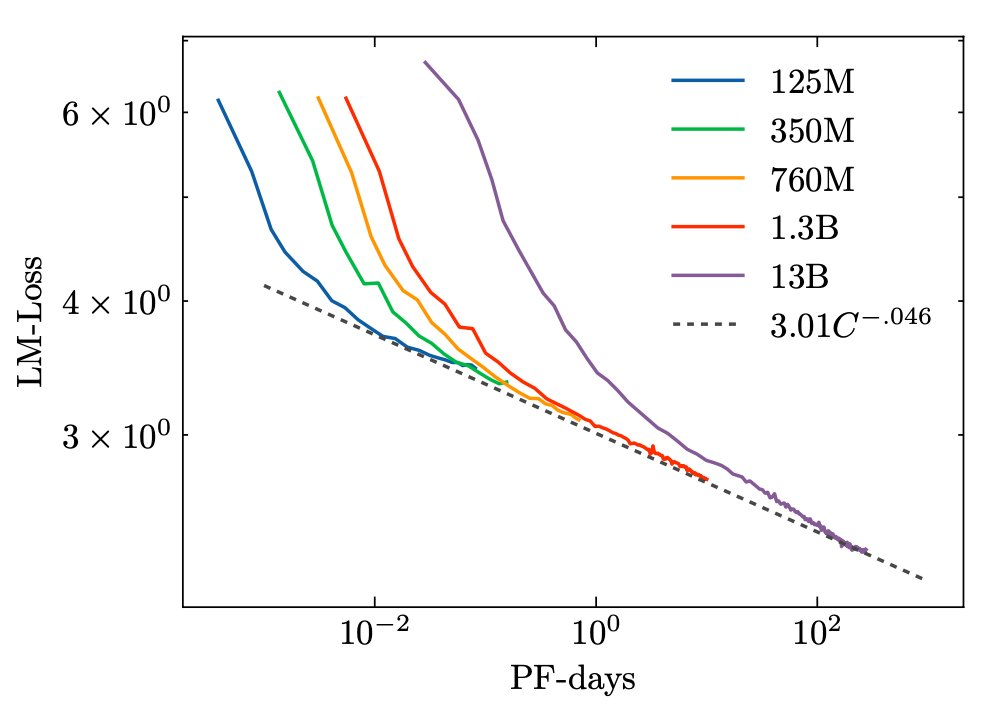
Zuerst haben wir Skalierungsgesetze abgeleitet, die uns eine obere Grenze für das „optimale“ Modell mit unseren Rechenressourcen geben: das wären etwa 392 Milliarden Parameter, die für etwa 165 Milliarden Tokens trainiert werden (mehr zu diesem Budget später). Aber Skalierungsgesetze berücksichtigen keine Kosten für das Servieren/Inferieren, die Leistung bei nachgelagerten Aufgaben usw. Außerdem müssen wir sicherstellen, dass ressourcenarme Sprachen während des Vortrainings genug Tokens sehen. Wir wollen nicht, dass unser Modell ganze Sprachen ohne vorheriges Training bewältigen muss, oder? Daher haben wir beschlossen, dass wir mindestens für 300-400 Milliarden Tokens vortrainieren sollten.
Compute (Rechenressourcen)
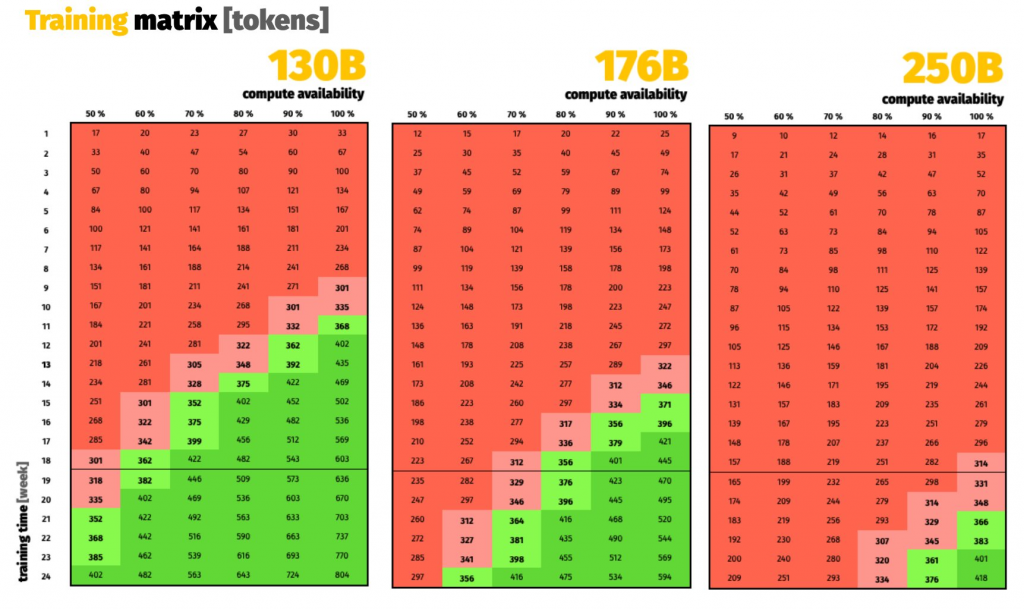
Dann haben wir unser Budget überprüft: 18 Wochen auf 384 A100 80GB, die uns von GENCI auf dem französischen Supercomputer Jean Zay zur Verfügung gestellt wurden, das sind 1.161.261 A100-Stunden! Wir haben geschätzt, wie viele Tokens wir für verschiedene Modellgrößen trainieren könnten, unter Berücksichtigung breiter „Sicherheitsmargen“ für mögliche Hindernisse. Ein klarer Gewinner zeichnete sich ab: ein Modell mit etwa 175 Milliarden Parametern, das uns eine gute Chance bietet, sogar etwas über 400 Milliarden Tokens zu erreichen.
Die Form des Modells
Um die Form zu entscheiden, haben wir uns zunächst heimlich angeschaut, wie andere große Modelle mit über 100 Milliarden Parametern aufgebaut sind. Wir haben auch ein wenig gelesen und einige wirklich interessante Arbeiten gefunden, wie sich die Form von Modellen mit zunehmendem Maßstab ändern sollte: insbesondere Kaplan et al. (2020) (ein Klassiker!) und Levine et al. (2020) (große Modelle sind zu fit! Macht sie klobiger!).
Geschwindigkeit zählt
Schließlich hat unser außergewöhnliche Ingenieur Hunderte von Konfigurationen benchmarked, um die schnellste zu finden. Mehr dazu könnt ihr in seinen Chroniken lesen. Es geht darum, die richtigen Zahlen zu finden und Effekte wie Tile/Wave-Quantisierung zu vermeiden. Wir endeten mit drei vielversprechenden finalen Konfigurationen. Wir lehnten (1) wegen ihrer großen Aufmerksamkeitsköpfe ab und wählten (3), da sie schneller als (2) war. Geschwindigkeit zählt: Jede zusätzliche Durchsatzsteigerung bedeutet mehr Gesamtrechenleistung, somit mehr Vortrainingstokens und ein besseres Endmodell.
Zusammenfassung
Nach intensiver Forschung und zahlreichen Experimenten haben wir uns für ein Modell mit etwa 175 Milliarden Parametern entschieden, das über 400 Milliarden Tokens vortrainiert wird. Durch die sorgfältige Auswahl der Modellform und die Optimierung der Trainingsgeschwindigkeit haben wir die Grundlage für ein leistungsstarkes mehrsprachiges Sprachmodell gelegt.